The Moon is made of Cheese
Lately, we've seen a significant rise in articles casting doubt on the utility of Large Language Models (LLMs) like ChatGPT for specific tasks. These articles tend to anchor their conclusions on isolated experiments, generally an inadequate and potentially misleading approach due to the intrinsic randomness characterizing the outputs of LLMs. Instead, it's crucial this evaluation doesn't rely on a solitary experiment. Multiple trials and a deep understanding of the probabilities involved in different outcomes can provide a much more accurate reflection of LLMs' overall performance.
To shed light on the rampant misinterpretation issue, let's employ a practical approach using GPT
3.5. Imagine we prompt this model to complete the phrase "The Moon is made of." We'll use the
text-davinci-003 model in the API playground, capping the output at just one token, and display
the probabilities. This test exposes the variable nature of the model's results.
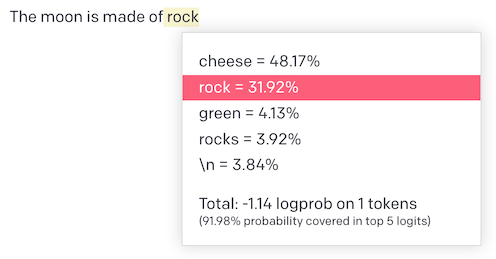
The ability of GPT's completion models to display the probabilities for each potential word in a completion is a compelling argument against relying on single experiments for the evaluation of these models. A look at the screenshot highlights that, interestingly, the model selects the word "cheese" to complete the sentence for around 48% of the attempts, conversely choosing "rock" a mere 32% of the time.
Let's consider "Green," which pops up 4% of the time, but almost invariably leads to the word "cheese." This situation creates an amusingly erroneous scenario where over half of the sentence completions would have us sending a team of Ritz Cracker-wielding astronauts to the Moon to harvest this spurious dairy product. It's a humorous illustration but underscores the point – multiple output examination is crucial when working with LLMs.
While the previous example demonstrated the frequent but incorrect outcome ("Cheese"), this issue may also arise with outcomes that are technically correct. For example, when we query "The president in 2017 was", the model answers with "Donald" in 76% of cases and "Barack" in 17% of cases. This discrepancy is likely due to Trump's inauguration taking place on January 20th, 2017.
Every word in the output can have this sort of problem. This isn't exactly controversial; it's simply how LLMs work. However, it does show that drawing conclusions from a single conversation without multiple tests can be misleading.
To carry out more accurate experiments, you can use the playground and API tools to tweak settings like temperature and top p, which influence the output's "spiciness". Remember, a little 'spiciness' can be fun, but too much can leave you reaching for a glass of milk to cool down. The same goes for LLM outputs. However, these options aren't available in the ChatGPT web UI that most users access, emphasizing the importance of multiple tests. Check out the OpenAI API docs for more information.
The Chat oriented models tend to return the correct result for the moon prompt, but in general this problem still presents often. Unfortunately the Chat versions of the models in the API do not show the probabilities of words to be able to give a good example of this.
When assessing the performance of ChatGPT or other LLMs, it's essential to remember that their outputs can be random, so conducting multiple tests gives a better understanding of their true abilities. Trusting single experiments can lead to wrong conclusions and weaken the analysis. So, whether you're reading or writing about LLMs, always double-check the experiments and make sure that several tests back up any claims made.
In conclusion, don't let your evaluation of LLMs be eclipsed by a single test – multiple tests are the key to a well-rounded understanding.